Hash Table
Key, Value 로 데이터를 저장하는 자료구조 중 하나 F(key)->hashCode->Index->Value
HashCode
입력데이터가 같으면 동일한 해시코드를 만들어내는 알고리즘

장점
검색속도가 매우 빠르다. 평균 시간복잡도 O(1)
해시코드는 정수다. 해시코드가 바로 Index로 사용되기 때문에 저장소에 바로 접근이 가능하다.
Index
Division Method
나눗셈을 이용하는 방법으로 입력값을 테이블의 크기로 나누어 계산한다. 테이블의 크기를 소수로 정하고 2의 제곱수와 먼 값을 사용해야 효과가 좋다고 알려짐
주소 = 입력값 % 테이블의 크기
Digit Folding
각 Key의 문자열을 ASCII 코드로 바꾸고 값을 합한 데이터를 테이블 내의 주소로 사용하는 방법
Multiplication Method
숫자로 된 Key값 K와 0과 1 사이의 실수 A, 보통 2의 제곱수인 m을 사용하여 다음과 같은 계산
h(k)=(kAmod1) × m
Univeral Hashing
다수의 해시함수를 만들어 집합 H에 넣어두고, 무작위로 해시함수를 선택해 해시값을 만드는 기법
ConvertToIndex(HashCode)
HashCode % array.size 로 Index 로 환산할 수 있다.
충돌현상(Collison)
해시함수의 알고리즘은 입력받은 키를 가지고 얼마나 잘 분배하느냐가 좋은 알고리즘에 속한다. O(N)
알고리즘이 아무리 좋아도 중복되는 키를 가질 수 밖에 없다.
충돌을 해결하기 위한 방법은 크게 2가지다.
개별 체이닝(Separate Chaining)
배열의 타입을 LinkedList로 선언하여 체이닝 하는 방법이 있다.
LinkedList에 데이터가 체이닝 된다면 검색 속도는 O(N)이 될 수 있다.

오픈 어드레싱(Open Addressing)
무한정 저장할 수 있는 체이닝 방식과 달리, 오픈 어드레싱 방식은 전체 슬롯의 개수 이상은 저장할 수 없다. 충돌이 일어나면 테이블 공간 내에서 탐사(Probing)를 통해 빈 공간을 찾아 해결하며, 이 때문에 개별 체이닝 방식과 달리, 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장은 없다.
저장된 데이터가 적으면 성능이 좋은편이나, 수용률이 넘어서게 되면 저장/조회 성능이 모두 점점 떨어지게 된다. 이를 해결하는 방법으로 더 큰 리스트를 만들어 적당한 타이밍에 점진적으로 몇 개씩 옮기다가 다 옮기면 기존 테이블을 제거하고 확장하는 방식도 있다.
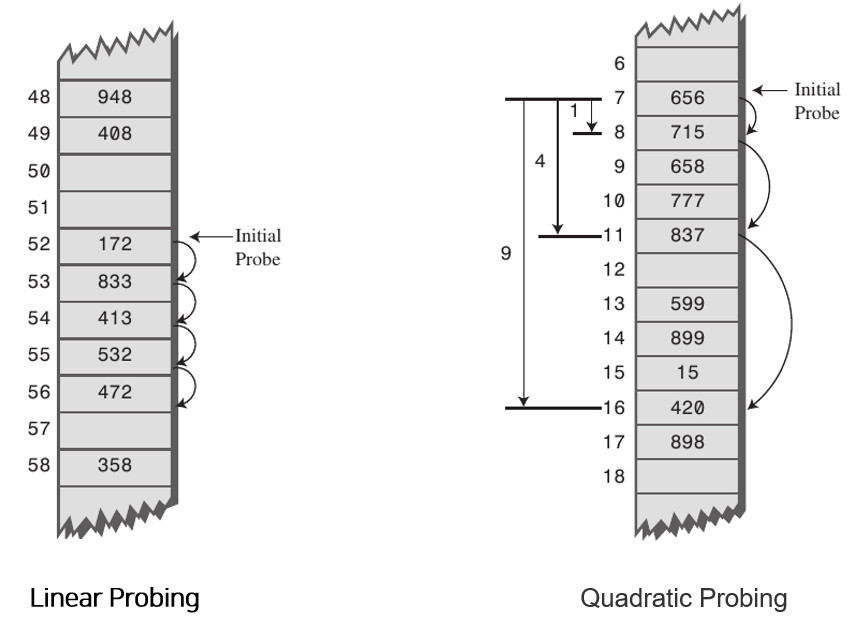
- Linear Probing
- 현재의 버킷 index로부터 고정폭 만큼씩 이동하여 차례대로 검색해 비어 있는 버킷에 데이터를 저장
- Quadratic Probing
- 해시의 저장순서 폭을 제곱으로 저장
- 예를 들어 처음 충돌이 발생한 경우에는 1만큼 이동하고 그 다음 계속 충돌이 발생하면 2^2, 3^2 칸씩 옮김
- Double Hashing Probing
- 해시된 값을 한번 더 해싱하여 해시의 규칙성을 없앰
- 해시된 값을 한번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법들보다 많은 연산을 함
Java의 HashMap과 HashTable 차이
HashTable은 synchronized 지원
- HashTable
- 동기화 지원
- HashMap
- 동기화 미지원
댓글남기기